
Nous pouvons tirer des leçons de plus de deux décennies de progrès visant à rendre les moteurs de recherche pratiques et utiles pour les internautes. Et le modèle RAG ( Retrieval Augmented Generation) s’avère une solution prometteuse pour combler le fossé entre la recherche et l'application de l'intelligence artificielle (IA). Cette technologie offre une approche efficace pour le développement de systèmes d'IA plus fiables et adaptables, à condition de respecter certains critères clés pour l'avenir.
Le défi du « fossé » en IA
La génération augmentée de récupération (RAG ou Retrieval Augmented Generation en anglais) a attiré l'attention de nombreuses entreprises cherchant à extraire de la valeur de leurs données textuelles non structurées. La RAG est une approche architecturale permettant d’optimiser le résultat d'un grand modèle de langage. Ce processus s’appuie sur une base de connaissances fiable externe aux sources de données utilisées afin de l'entraîner avant de générer une réponse. La RAG étend les capacités déjà très puissantes des LLM à des domaines spécifiques ou à la base de connaissances interne d'une organisation, et ce sans qu'il soit nécessaire de réentraîner le modèle. Cette approche économique permet d’améliorer les résultats du LLM tout en restant cohérents, précis et utiles dans de nombreux contextes.
Ces entreprises ont procédé à des évaluations initiales de la RAG dans le cadre de divers cas d'utilisation. Ces expérimentations ont démontré que l’approche RAG actuelle utilisée pour développer des Chatbots IA ne répond pas aux attentes des utilisateurs finaux. En réponse, la technologie RAG a fait l'objet de révisions importantes. Elle intègre désormais le traitement de requêtes complexes et les graphes de connaissances. Malgré les progrès fulgurants, l’approche RAG reste confrontée à des défis, tels qu'une faible précision dans les tâches en aval et l'imprévisibilité dans les réponses. Ces lacunes entravent son adoption généralisée dans des applications concrètes.
La création de chatbots à partir de données est passée de l'attente d'un modèle prêt à l'emploi à un besoin d'une stratégie plus approfondie. Elle nécessite une personnalisation, une expérimentation constante et un développement, comme l'illustre ce récent article de l'UC Berkeley. Les chatbots personnalisés basés sur le LLM ressemblent désormais à une autre solution d'IA "non reproductible". Ils proposent de nombreux paramètres complexes, nécessitant des équipes spécialisées travaillant pendant des années. Ce développement implique des ressources coûteuses pour produire quelque chose qui trouve encore difficilement sa place dans la production réelle.
Heureusement, il y a une ouverture positive à ces expérimentations ! Ce retour d'information sur le long terme nous permet aujourd’hui d’améliorer la pertinence sémantique des moteurs de recherche et de recommandation.
Avant d'explorer ce feedback implicite, comprenons rapidement pourquoi la recherche pilotée par LLM ne répond pas aux attentes des utilisateurs.
Pourquoi la recherche basée sur les LLM ne répond pas aux attentes des utilisateurs ? Parce que RAG n'a aucune idée de la dynamique commerciale quotidienne
Les entreprises se sont empressées de créer des agents intelligents par la recherche sémantique sur des données non structurées à l'aide de grands modèles de langage (LLM). Ces développements reposaient sur l'hypothèse raisonnable que les demandes des utilisateurs sont souvent répétitives et factuelles. En effet, l’IA permet d’automatiser facilement des requêtes dont les réponses attendues ne changent pas.
Toutefois, l'attrait de l'IA générative (GenAI) réside dans sa capacité à dépasser le domaine des requêtes factuelles statiques. Même les méthodes existantes, telles que le "système de cache intelligent" et les chatbots basés sur des règles datant d'avant l'ère de la GenAI, sont efficaces pour les questions factuelles répétitives.
Phénomènes de la loi de puissance
Une fois que l'on a dépassé le stade des requêtes factuelles statiques et répétitives, on ne peut plus ignorer les données dynamiques quotidiennes propres à l'entreprise. La distribution des requêtes et les réponses attendues, quel que soit le domaine d'activité, suivent généralement la loi de puissance. Ainsi, l’IA évolue dans le temps en cohérence selon cette règle mathématique. Illustrons ce phénomène par un exemple.
Prenons l'exemple d'un service d'assistance automatisé à la clientèle, où un grand nombre de clients signalent le problème suivant : « Ma carte de crédit ne fonctionne pas ». On a pu identifier par le passé 10 causes différentes pour ce problème. Il pouvait s’agir d'une erreur de saisie d'informations par le client, d’un dépassement des limites de crédit, de problèmes d'autorisation bancaire ou encore de l'utilisation de cartes non prises en charge, comme American Express. Supposons qu'au cours de la semaine écoulée, 90 % des cas concernaient des clients utilisant une carte American Express. Leur carte était systématiquement refusée. Si un client signale à nouveau ce problème, un agent humain, informé des tendances récentes, répondra probablement : « Utilisez-vous une carte American Express ? Nous avons souvent constaté ce problème ces derniers temps. » Or, les grands modèles linguistiques (LLM) ne comprennent que l'anglais de base. Et leur raisonnement n’implique pas l’analyse de la « tendance actuelle ». Un agent conversationnel classique répondrait certainement en fournissant la liste générique de dix possibilités au client. Cette énumération peut provoquer de la frustration de la part d’un internaute espérant une réponse précise.
Tout comme les moteurs de recherche, la satisfaction globale des utilisateurs dépend de la pertinence de la recherche sémantique pour les requêtes les plus populaires. Même si la précision de RAG est de 99 % et qu'il ne parvient pas à retrouver la bonne information sur 1 % des requêtes populaires, nous finissons par agacer la quasi-totalité des clients. Ce qui est intéressant, c'est que la popularité dérive avec le temps. Cela signifie que 1 % des requêtes importantes ne seront plus les mêmes au bout d'un certain temps.
Pipelines complexes de recherche et d'étiquetage des données pour un réglage fin
Le marché reconnaît progressivement que la véritable valeur de l'IA réside dans la révision fréquente des pipelines d'IA avec une base de réglage fin et/ou des modèles d'intégration. Cette révision assure ainsi une recherche personnalisée.
Le réglage fin est un processus de modification d'un modèle de base à usage général pour le faire fonctionner pour un cas d'utilisation spécialisé. Il permet d'intégrer des données de l'entreprise au-delà des données d'Internet pour surpasser les modèles de base. Il permet ainsi de générer des résultats cohérents, de réduire la créativité et de personnaliser le modèle.
Ce réglage fin implique généralement un étiquetage manuel des données, ce qui représente un travail minutieux. Par conséquent, une nouvelle tendance émerge consistant à l'augmentation des acteurs offrant des services d'étiquetage et des tableaux de bord. Elle permet aux experts du domaine d'apporter des données de formation précieuses. Les services d'étiquetage des données représentent un autre défi auquel la communauté de l'IA s'est attaquée dans le passé avec un succès limité.
Feedback implicites et personnalisation : des étiquettes de haute qualité sans étiquetage manuel des données
L’IA générative a permis d’importants progrès de la recherche sémantique. Depuis le début des années 2000, les moteurs de recherche ont effectivement éliminé le besoin d'étiquetage manuel des données en s'adaptant perpétuellement aux comportements des utilisateurs. La clé consiste à exploiter le retour d'information implicite et à s'appuyer fortement sur les données de clics librement disponibles dans les interactions avec les utilisateurs.
Comprendre le feeback implicite et les données de clics
Le retour d'information implicite consiste à obtenir des données étiquetées à partir d'interactions humaines naturelles sans étiquetage explicite. Prenons l’exemple d’un système orienté vers l'utilisateur qui présente des résultats de recherche ou un flux de réseaux sociaux. Les actions de base de l'internaute telles que les clics, les extensions, le survol de la souris, le mouvement des yeux et le temps d'attente peuvent être suivis. L'analyse de ces actions fournit un retour d'information essentiel. Ainsi, si un internaute cherche « orange » et clique (ou passe plus de temps) sur les résultats liés à la société Orange plutôt que le fruit, cela indique, sans étiquetage explicite, la signification sémantique de « orange » dans le contexte donné.
En analysant les données de clics, l’approche RAG peut déduire les préférences et les intentions des utilisateurs. Elle offre ainsi une compréhension plus fine de leurs interactions avec le système.
L'importance des étiquettes implicites
Au début des années 2000, des études sur le comportement humain et le contenu de l'information dans des signaux implicites librement accessibles ont permis d’améliorer la précision de la recherche basée sur l'apprentissage. Le succès des moteurs de recherche et de recommandation, tels que Google, dépend de leur capacité à s'adapter automatiquement au comportement de l'utilisateur au fil du temps, en fonction de l'utilisation et des clics. Sans cette capacité et ce retour d'information implicite, un moteur de recherche reposant uniquement sur la pertinence textuelle, le langage ou le raisonnement commun a peu de chances de fournir le niveau souhaité de pertinence de la recherche.
Répondre aux attentes des entreprises avec une solution reproductible : la technologie RAG
La technologie RAG existante et la technologie RAG avancée ne permettent pas d'automatiser complètement les tâches complexes ou de « franchir le fossé » sans acquérir une expertise substantielle dans le domaine et une formation continue par le biais d'une mise au point perpétuelle. Toutefois, une approche progressive, semblable à l'évolution des voitures autonomes, avec un retour d'information implicite, peut changer la donne et permettre de franchir le cap de la production.
Third AI illustre cette disparité en opposant deux scénarios.
RAG existant (Non reproductible dans les domaines et les cas d'utilisation)
Si l'on suit la recommandation standard, il semble impossible de parvenir à la répétabilité dans tous les cas d'utilisation. Il faut une équipe spécialisée pour entreprendre les tâches suivantes pour chaque cas d'utilisation spécifique :
- Collecte des données
- Étiquetage des données
- Ajustement continu des modèles d'intégration
- Reconstruction et réindexation des bases de données vectorielles complètes pour chaque affinement du modèle d'intégration
Ce n'est qu'après avoir obtenu une précision satisfaisante que nous pouvons contourner les contraintes de production et de déploiement. Cette approche ressemble aux anciens pipelines d'intelligence artificielle, où les statistiques indiquent que 87 % des modèles ne parviennent pas à atteindre la production en raison de l'inadéquation entre l'utilisation réelle et les tests hors ligne.
RAG dont nous avons besoin (répétable dans tous les domaines et tous les cas d'utilisation)
Il n'est pas réaliste de s'attendre à une automatisation complète et immédiate des solutions RAG spécialisées par domaine. Mais nous pouvons progresser vers l'automatisation complète de manière incrémentale et par étapes. Le concept consiste à lancer un logiciel RAG perpétuellement adaptatif conçu pour une mise au point continue en ligne. Ce système s'améliore ainsi quotidiennement. Le logiciel, capable d'autoréglage, gère l'ensemble du cycle de vie de l'IA, du pré-entraînement au déploiement en passant par le réglage fin. Nous introduisons le logiciel dans un mode d'automatisation partielle ou fictive, parallèlement aux systèmes existants essentiellement manuels. Il enregistre en permanence les clics implicites de l'utilisateur, les statistiques du regard et d'autres réactions naturelles.
Le système RAG s'affine automatiquement en exploitant les données d'utilisation et de retour d'information implicite. Une fois suffisamment affiné, le système passe de l'absence d'automatisation à l'automatisation partielle, puis à l'automatisation totale. A noter que le logiciel reste reproductible dans tous les cas d'utilisation et qu'il est toujours prêt pour la production, puisqu'il fonctionne (ou s'assombrit) en temps réel avec les systèmes existants.
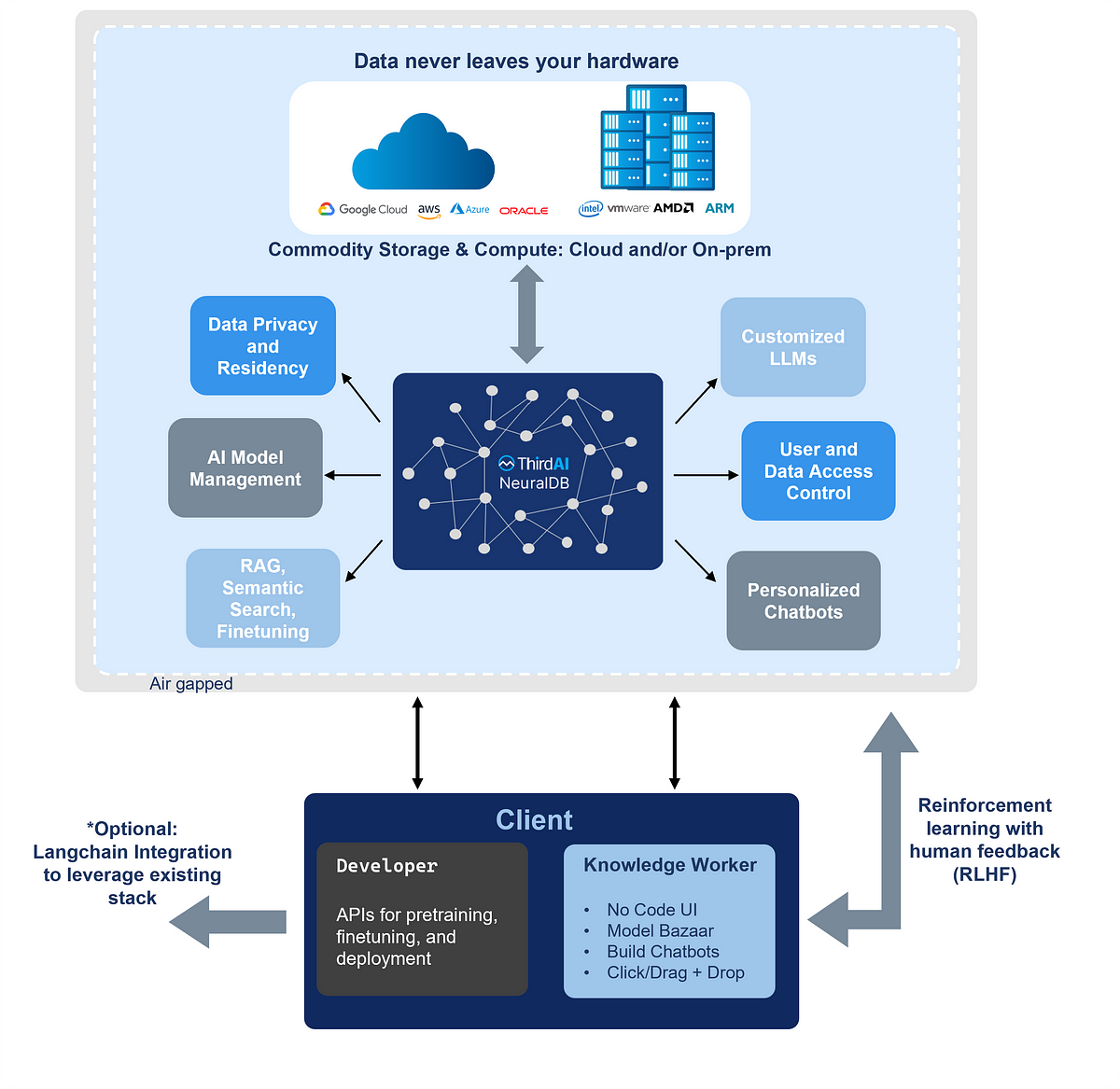
NeuralDB de ThirdAI
Conçu précisément pour être le système RAG « dont nous avons besoin », NeuralDB se distingue par ses différentiateurs technologiques. Des études de cas de la technologie développée par ThirdAI illustrent les améliorations significatives de la pertinence des recherches obtenues grâce à un réglage en ligne perpétuel.
Partenaire exclusif de ThirdAI, Cercle Business a intégré NeuralDB dans son chatbot MonIA. Il permet de proposer des réponses plus précises et plus naturelles en analysant les intentions et les préférences des internautes. Grâce à cette collaboration, MonIA améliore encore davantage ses performances et sa pertinence dans la génération de réponses et de recommandations personnalisées.
___________